
State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications
Abstract
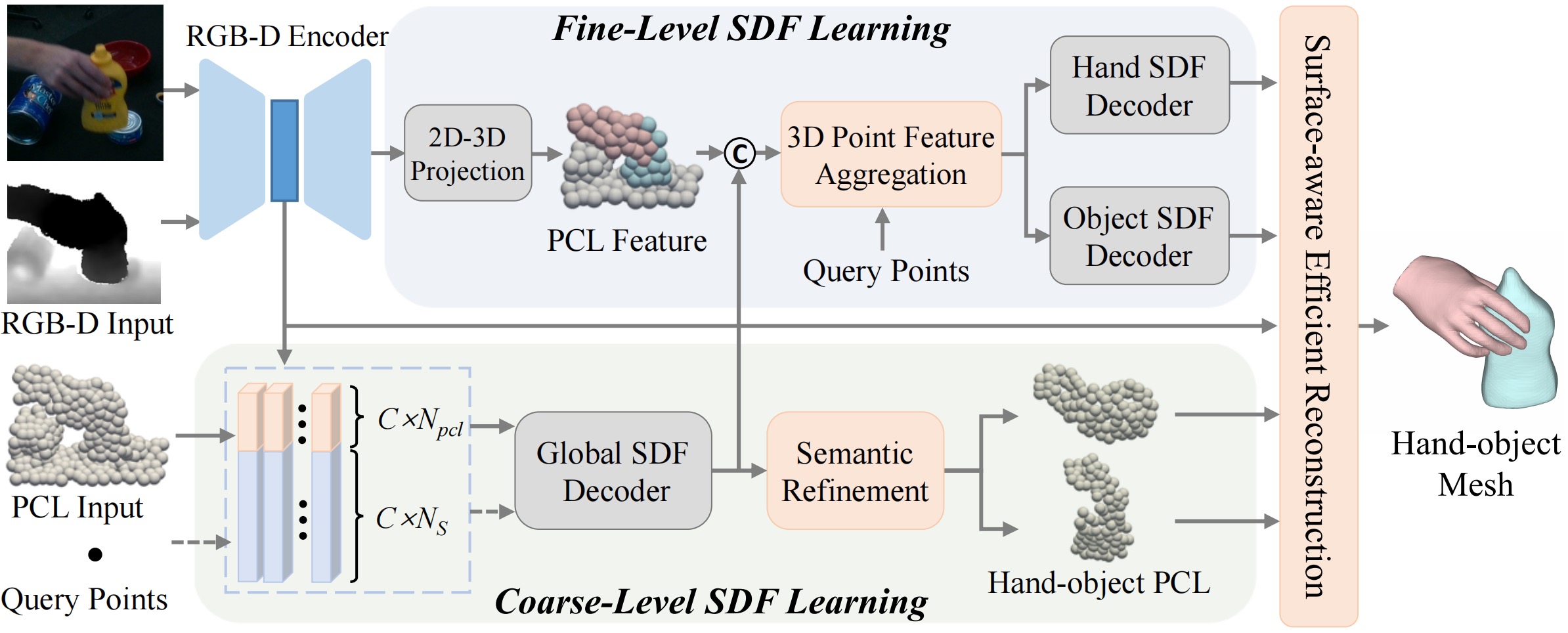
Recent research has explored implicit representations, such as signed distance function (SDF), for interacting hand-object reconstruction. SDF enables modeling hand-held objects with arbitrary topology and overcomes the resolution limitations of parametric models, allowing for finer-grained reconstruction. However, directly modeling detailed SDFs from visual clues presents challenges due to depth ambiguity and appearance similarity, especially in cluttered real-world scenes. In this paper, we propose a coarse-to-fine SDF framework for 3D hand-object reconstruction, which leverages the perceptual advantages of RGB-D modality in visual and geometric aspects, to progressively model the implicit field. Specifically, we model a coarse SDF for visual perception of overall scenes. Then, we propose a 3D Point-Aligned Implicit Function (3D PIFu) for fine-level SDF learning, which leverages both local geometric clues and the coarse-level visual priors to capture intricate details. Additionally, we propose a surface-aware efficient reconstruction strategy that sparsely performs SDF query based on the hand-object semantic priors. Experiments on two challenging hand-object datasets show that our method outperforms existing methods by a large margin.
Overview
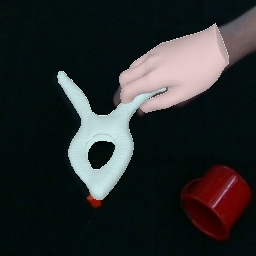
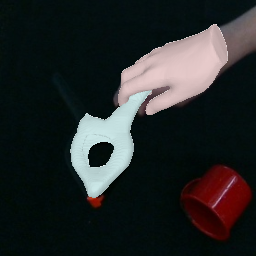
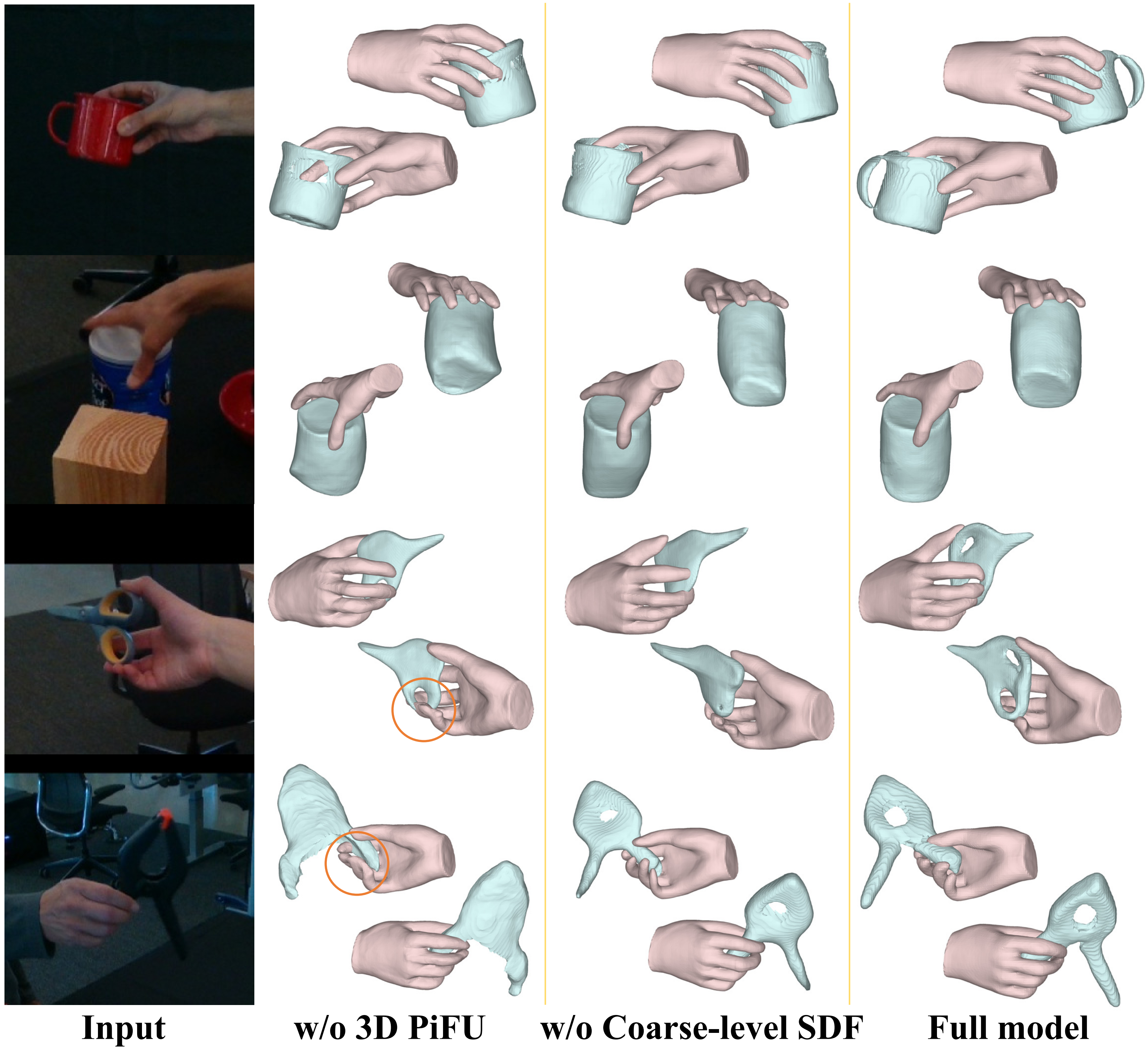
Comparison with Baseline
Input Image
Ours
Ours
gSDF
gSDF





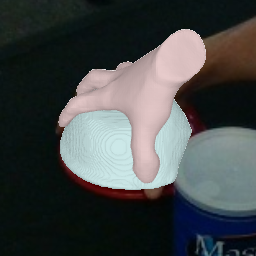
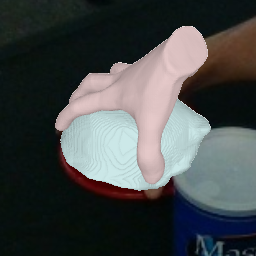


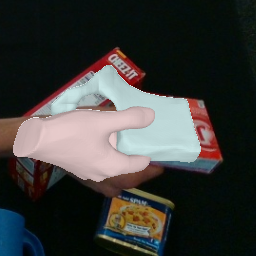

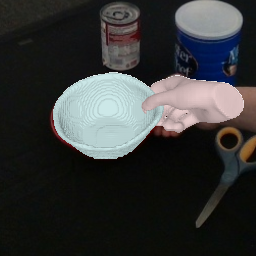

Result


Bibtex
@inproceedings{liu2025coarse,
title={Coarse-to-Fine Implicit Representation Learning for 3D Hand-Object Reconstruction from a Single RGB-D Image},
author={Liu, Xingyu and Ren, Pengfei and Wang, Jingyu and Qi, Qi and Sun, Haifeng and Zhuang, Zirui and Liao, Jianxin},
booktitle={European Conference on Computer Vision},
pages={74--92},
year={2025},
organization={Springer}
}