
AIGC图像视频生成
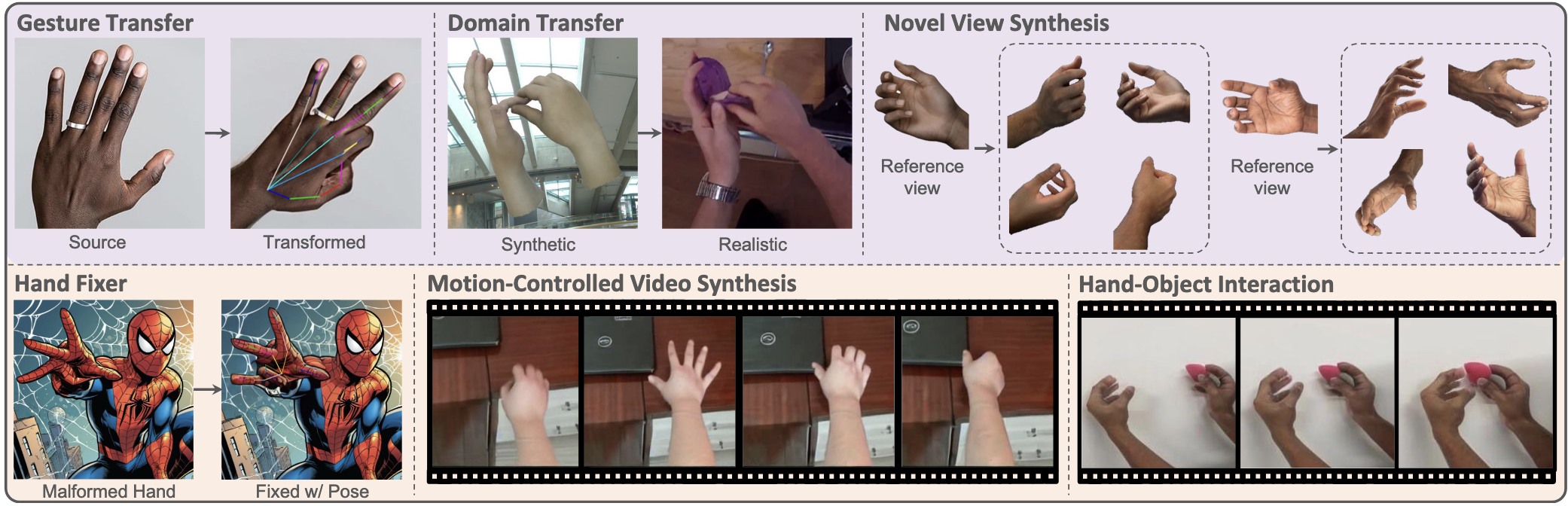
图像与视频生成(AIGC, Artificial Intelligence Generated Content)已成为视觉内容生成领域的重要研究方向。其中,手部图像的高保真生成作为AIGC在精细级人体建模中的关键课题,因其在人机交互、虚拟现实、动作捕捉等场景中的广泛应用而备受关注。相较于脸部或人体生成,手部因其自由度高、形变复杂、局部结构精细且易被遮挡,生成难度显著增加。因此,研究如何在保留手部纹理细节的同时实现姿态准确、外观一致、可控视角下的图像合成,对于提升虚拟交互的真实感和沉浸感具有重要意义。我们重点关注高保真、结构一致、跨视角的手部图像生成机制,融合多种条件形式,包括显式/隐式的姿态表示(如2D/3D关键点、深度图、手部掩膜等)与图像外观特征,以实现更加灵活的手部操控与外观迁移。我们致力于构建一个具备多源条件整合能力的通用生成框架,支持多身份、多风格、多场景的高质量合成。该框架将为多个下游任务提供支撑,包括动作驱动的视频生成与手物交互视频合成,在数字人建模、虚拟交互与影视创作中展现广阔潜力。
-
A Dual-Branch 3D Spatial-Aware Latent Diffusion for Realistic Hand Depth Image Synthesis
Shuang Hao, Pengfei Ren*, Lei Zhang, Haifeng Sun, Pan Ting, Menghao Zhang, Cong Liu, Qi Qi†, Jianxin Liao, Jingyu Wang†