Multi-view 3D human pose estimation (HPE) leverages complementary information across views to improve accuracy and robustness. Traditional methods rely on camera calibration to establish geometric correspondences, which is sensitive to calibration accuracy and lacks flexibility in dynamic settings. Calibration-free approaches address these limitations by learning adaptive view interactions, typically leveraging expressive and flexible continuous representations. However, as the multiview interaction relationship is learned entirely from data without constraint, they are vulnerable to noisy input, which can propagate, amplify and accumulate errors across all views, severely corrupting the final estimated pose. To mitigate this, we propose a novel framework that integrates a noise-resilient discrete prior into the continuous representation-based model. Specifically, we introduce the UniCodebook, a unified, compact, robust, and discrete representation complementary to continuous features, allowing the model to benefit from robustness to noise while preserving regression capability. Futhermore, we propose an attribute-preserving and complementarity-enhancing Discrete-Continuous Spatial Attention (DCSA) mechanism to facilitate interaction between discrete priors and continuous pose features. Extensive experiments on three representative datasets demonstrate that our approach outperforms both calibration-required and calibration-free methods, achieving state-of-the-art performance.
Overview
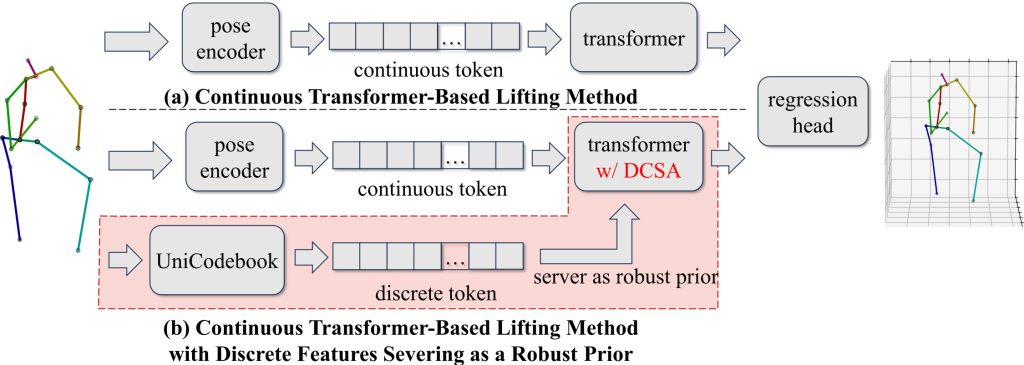
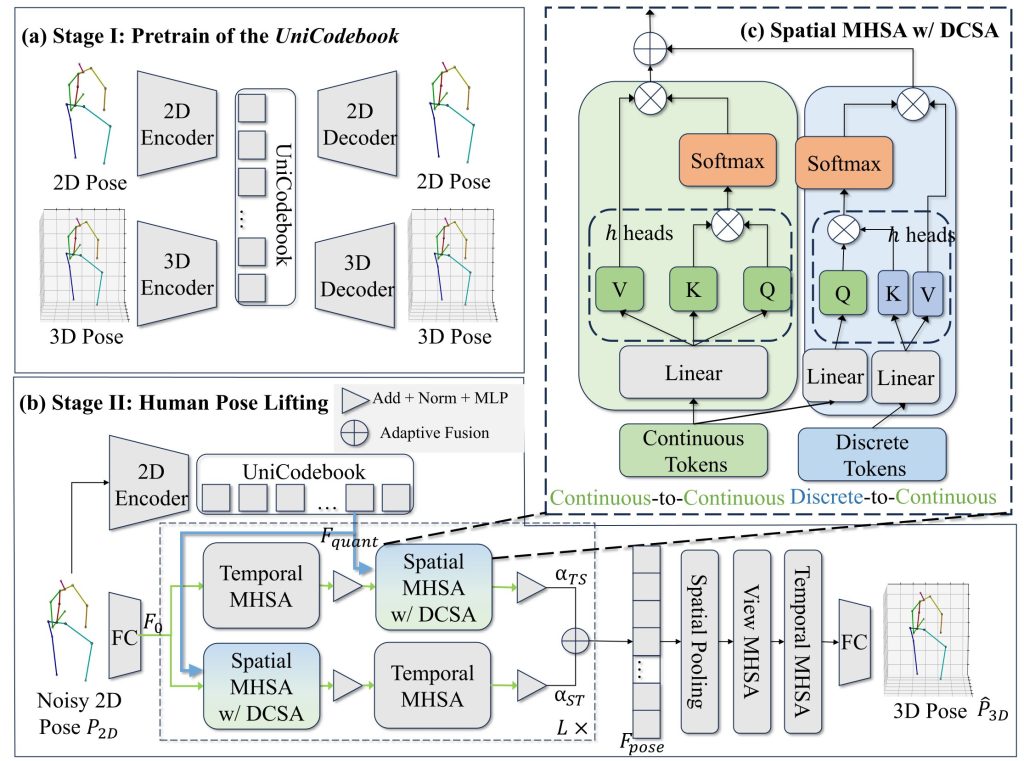
Compared with current SOTA: (a) Continuous transformer-based lifting method, which directly processes 2D pose inputs to estimate 3D poses. (b) Proposed method, which integrates discrete features as a robust prior within a continuous transformer-based framework, enhancing robustness to noisy 2D inputs and improving pose estimation accuracy.Two stages of the proposed calibration-free multiview 3D human pose lifting pipeline (a, b) and the detailed structure of the Spatial Multi-Head Self-Attention (MHSA) with Discrete-Continuous Spatial Attention (DCSA) (c). In Stage I, we construct the UniCodebook, a unified discrete representation space, through a multi-strategy training scheme (2Dto2D, 2Dto3D, 3Dto2D, and 3Dto3D). In this space, both 2D and 3D poses are encoded as sets of discrete tokens in this shared space to bridge the representation gap between 2D and 3D data. In Stage II, a transformer-based continuous model is employed for pose lifting, where codebook tokens generated from the UniCodebook are injected into the hybrid spatial attention block. Here, the proposed DCSA mechanism is integrated with conventional MHSA to facilitate effective fusion between the noise-resilient discrete priors and expressive continuous pose features, which enhances the robustness to noisy 2D input.
Qualitative Results
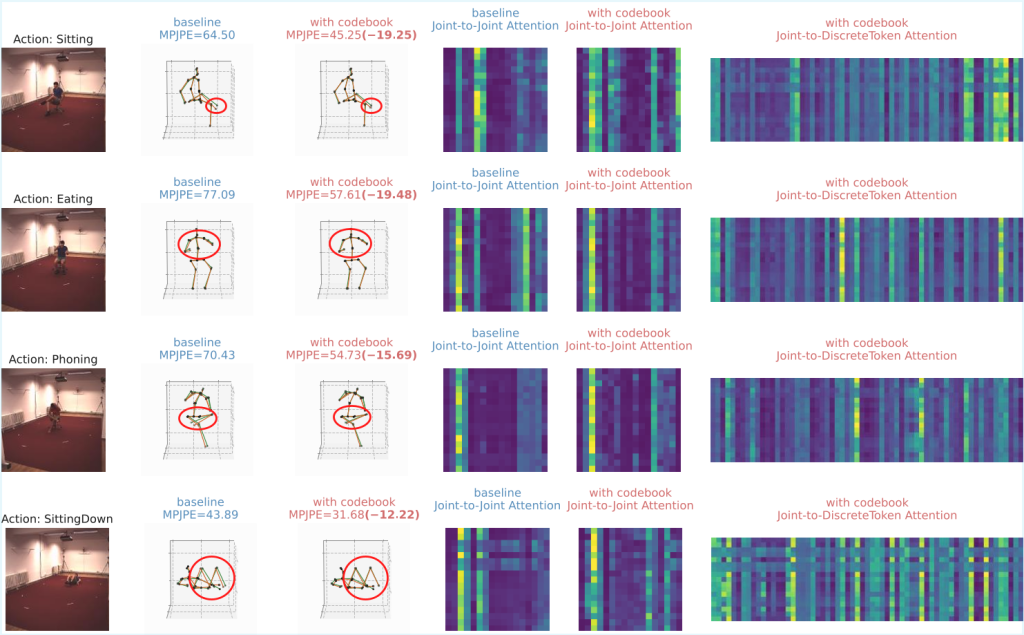
Qualitative comparisons of 3D human poses estimated by the baseline and the baseline with codebook. The orange skeleton denotes the prediction, while the green skeleton indicates the ground truth. Additionally, we visualize the joint-to-joint attention heatmap and DCSA heatmap (joint-to-DiscreteToken Attention in the figure) in the first spatial block. Both models are trained with 4 views, but for space efficiency, we only present the images and predictions from view 0.
Comparison with SOTA
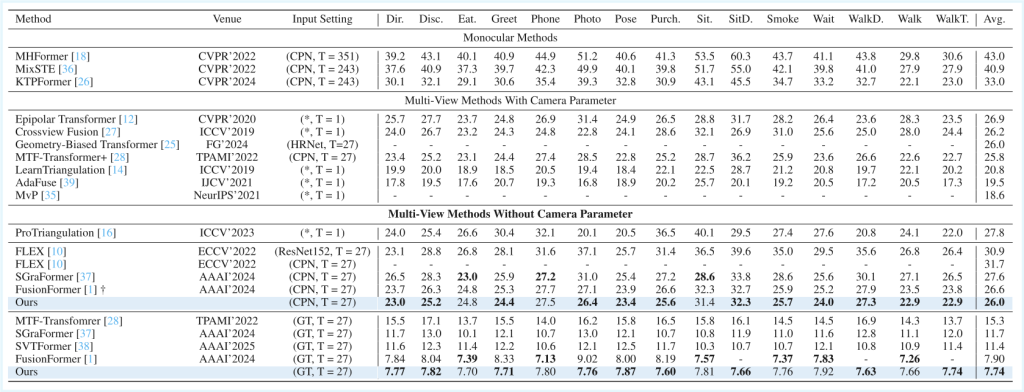
Results on Human3.6M are reported using MPJPE as the evaluation metric. CPN, HRNet and ResNet152 are different 2D pose detectors. GT means using ground truth 2D pose. * means this is an image-to-3d method. † indicates our reimplementation. T represents the number of frames.
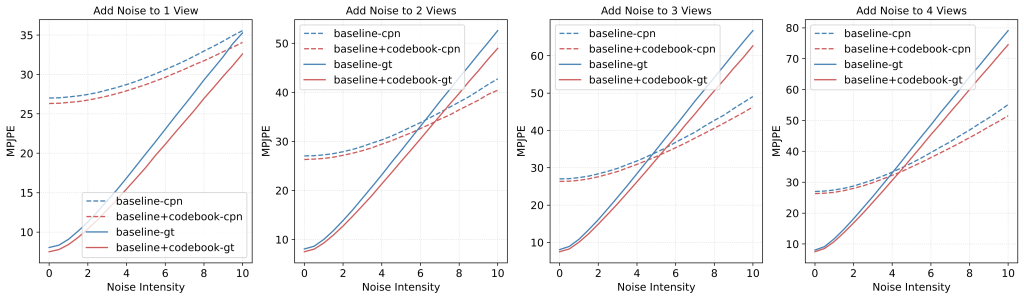
Noise Robustness
Comparison of MPJPE error across four models (i.e., baseline trained on H36M CPN, baseline with codebook trained on H36M CPN, baseline trained on H36M GT, and baseline with codebook trained on H36M GT) under varying noise intensities without retraining. For each instance (consisting of multi-view 2D poses of the same person at the same timestamp), we randomly select 1 to 4 views and add Gaussian noise with zero mean and a standard deviation of ”Noise Intensity” pixels to each 2D joint. For models trained on H36M CPN, we evaluate them using H36M CPN test data with extra noise. Similarly, models trained on H36M GT are evaluated with H36M GT test data with extra noise. The results show that models with the codebook exhibit robustness across all noise levels, with greater robustness observed at higher noise intensities.
Bibtex
@inproceedings{chen2025unicodebook,
title={{Unified 2D-3D Discrete Priors for Noise-Robust and Calibration-Free Multiview 3D Human Pose Estimation}},
author={Chen, Geng and Ren, Pengfei and Jian, Xufeng and Sun, Haifeng and Zhang, Menghao and Qi, Qi and Zhuang, Zirui and Wang, Jing and Liao, Jianxin and Wang, Jingyu},
booktitle={Advances in Neural Information Processing Systems},
year={2025}
}