
State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications
Abstract
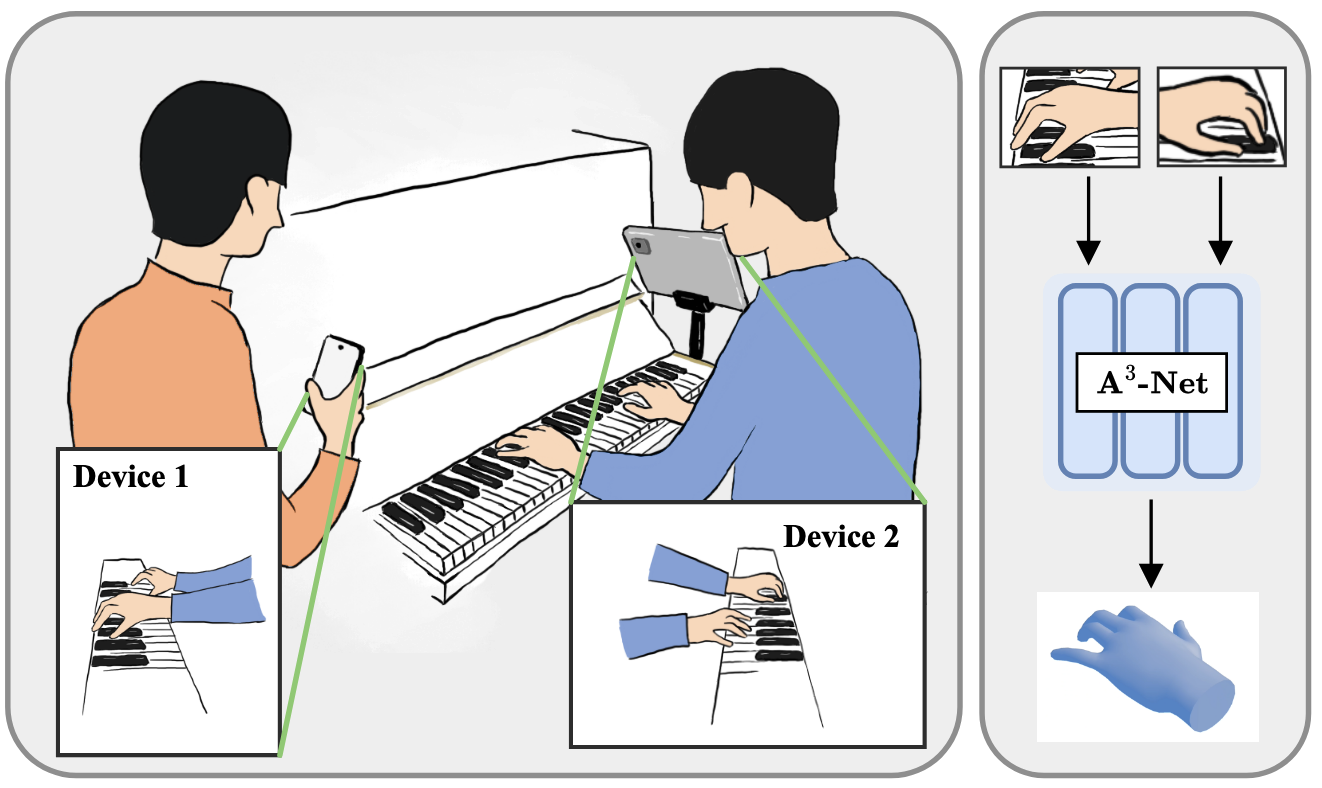
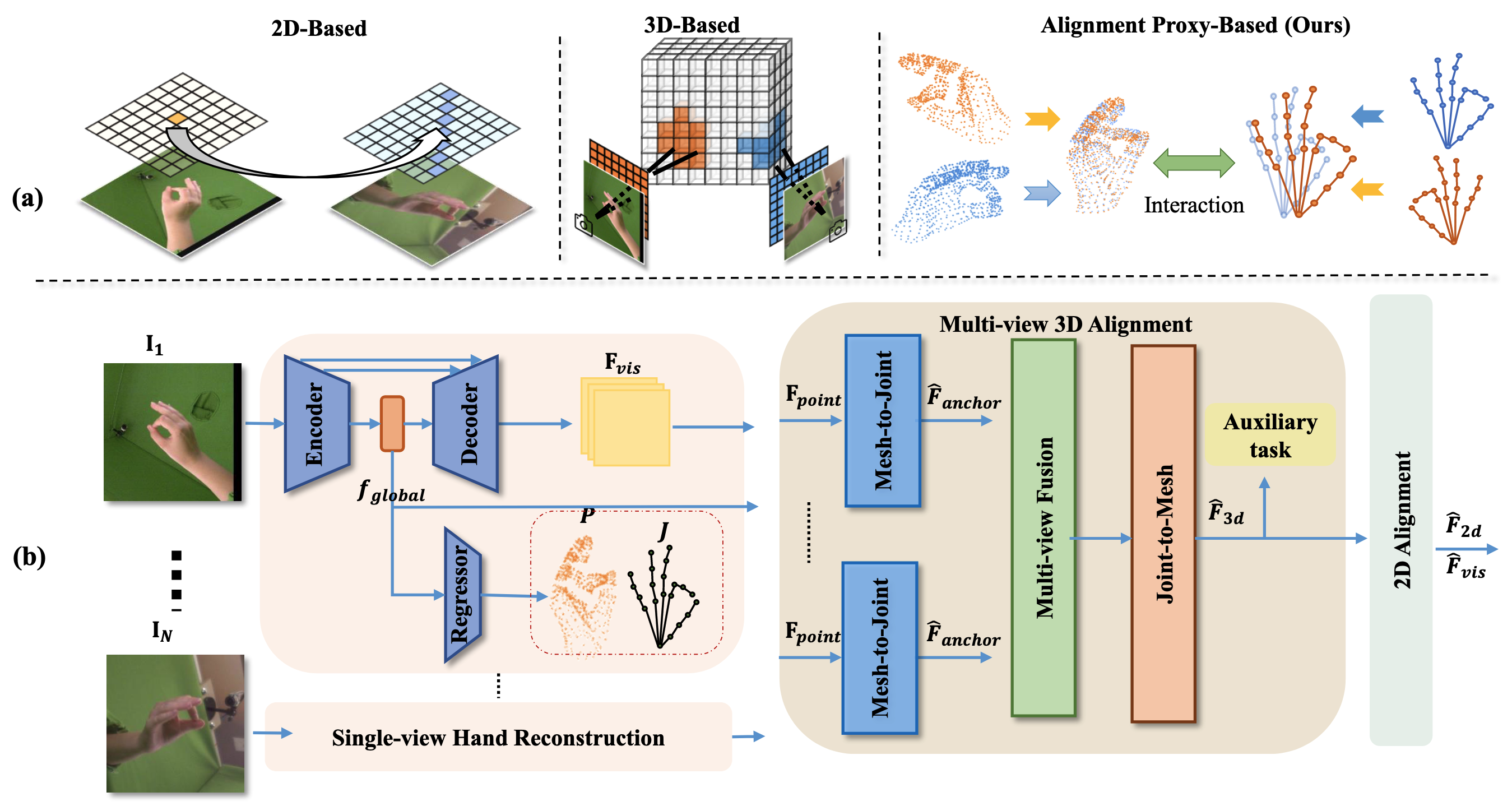
Precise 3D hand posture is essential for learning musical instruments. Reconstructing highly precise 3D hand gestures enables learners to correct and master proper techniques through 3D simulation and Extended Reality. However, exsiting methods typically rely on precisely calibrated multicamera systems, which are not easily deployable in everyday environments. In this paper, we focus on calibration-free multi-view 3D hand reconstruction in unconstrained scenarios. Establishing correspondences between multi-view images is particularly challenging without camera extrinsics. To address this, we propose A3-Net, a multi-level alignment framework that utilizes 3D structural representations with hierarchical geometric and explicit semantic information as alignment proxies, facilitating multi-view feature interaction in both 3D geometric space and 2D visual space. Specifically, we first perfrom global geometric alignment to map multi-view features into a canonical space. Subsequently, we aggregate information into predefined sparse and dense proxies to further integrate cross-view semantics through mutual interaction. Finnaly, we perfrom 2D alignment to align projected 2D visual features with 2D observations. Our method achieves state-of-the-art results in task of multi-view 3D hand reconstruction, demonstrating the effectiveness of the proposed framework.
Video
Overview
Comparison with SOTA
